文件下载
要考虑文件来自客户端还是服务端。
如果是服务端存在的文件,优先考虑使用响应头为Content-Disposition:attachment的方式,使用 a 标签下载,有更好的兼容性。如果需要客户端生成文件,再考虑使用 createObjectURL 或 File Saver 等库的方式。
a 标签下载
最简单的方式。
创建一个 a 标签,href 属性指向文件地址,设置 download 属性为下载的文件名字。<a href="http:/your-site/test.png" download="test.png">
//根据后端提供的文件接口地址,实现文件下载的功能:
function downloadFile(url, fileName) {
const a = document.createElement('a');
a.href = url;
a.download = fileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
}
注意:使用 download 属性需要添加文件扩��展名。
问题:
- 只支持 get 请求。
- 如果文件地址 url 如果是跨域的,a 标签的 download 属性不生效,无法自定义文件的名字。
- 无法监听请求是否成功,文件是否正常下载。(也许可以先发一个 HEAD 请求测试一下 api 地址是否正常?
通过 blob 前端生成下载连接
function downloadFile(path, name) {
axios({
url: path,
method: 'get',
responseType: 'arraybuffer', // /blob
}).then((res) => {
const blob = new Blob([res.data], { type: res.headers['content-type'] }); //要保证文件的类型
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.style.display = 'none';
a.href = url;
a.download = name;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
});
}
问题:
- 支持不同请求方式的 api
- 耗费浏览器内存,需要前端完全接收完文件再生成前端下载地址,速度慢且容易崩溃。
- 对大文件下载不友好,前期接收文件流时用户无感知,以为没有进行下载,用户体验不好。
业务中遇到的是大文件下载且需要自定义文件名,服务器文件地址又是不同域的。可以用上面转成二进制流下载并重命名文件。
但这样会耗费比较大的浏览器内存,需要前端完全接收完文件再生成前端下载地址,速度慢且容易崩溃。
最后采取的方式是在请求接口中传递一个文件名参数给后端,后端返回使用这个文件名重命名的文件。这个文件名参数添加在了Content-Disposition这个响应头上,Content-Disposition:attachment;filename=xx.tar.gz,这样就实现了自定义文件名的需求,再配合 a 标签下载即可。
另外此处还遇到传递中文文件名,下载文件名乱码,响应头Content-Disposition的内容乱码,服务器端没有处理好正确解码方式的问题。
** 关于自定义文件名的问题**
如果在 nginx 中配置了反向代理,浏览器请求的地址是同源的,download 属性会生效。
但如果请求接口的响应头也设置了 Content-Disposition 中的 filename ,此时 响应头中设置的文件名的优先级是最高的,会使在 a 标签 download 属性设置的文件名不生效。
分块范围下载 blob,前端生成下载链接
利用 HTTP 分片下载的特性,分片传输 blob ,然后合并 blob 生成下载链接。
速度比上面直接传输完整 blob 流快很多,占用内存也相对小。(但还不清楚为啥这样占用内存会更小)。可以从当前页面取消下载,断点续传。
范围下载:响应��头需支持
Range。范围正确响应,响应头为 206。范围不合法,响应头为 416,表示客户端范围请求错误。
流程:
- 发送 HEAD 请求获取文件大小
- 计算文件分块
- 执行并发下载 asyncPool
- 合并 blob
- 利用 BlobURL 生成下载链接
const SIZE = 20 * 1024 * 1024; //分片大小
const CONTENT_LENGTH = xxxxx; //发一个head 请求,从接口获取文件大小
const download = async (url, filename,poolLimit=3) => {
let chunks = Math.ceil(CONTENT_LENGTH / SIZE); //分片个数
let chunksArray = [...new Array(chunks).keys()];
let results = await asyncPool(poolLimit, chunksArray, (i) => {
let start = i * SIZE;
let end = i + 1 === chunks ? CONTENT_LENGTH : (i + 1) * SIZE - 1;
return getBinaryContent(url, start, end, i);
});
results.sort((a, b) => a.index - b.index);
let arr = results.map((r) => r.data?.data);
console.log("arr", arr);
const blob = new Blob(arr, { type: "application/octet-stream" });
saveByBlob("mp4.mp4", blob);
};
//并行请求并发控制
async function asyncPool(poolLimit, array, iteratorFn) {
const ret = []; // 存储所有的异步任务
const executing = []; // 存储正在执行的异步任务
for (const item of array) {
// 调用iteratorFn函数创建异步任务
const p = Promise.resolve().then(() => iteratorFn(item, array));
ret.push(p); // 保存新的异步任务
// 当poolLimit值小于或等于总任务个数时,进行并发控制
if (poolLimit <= array.length) {
// 当任务完成后,从正在执行的任务数组中移除已完成的任务
const e = p.then(() => executing.splice(executing.indexOf(e), 1));
executing.push(e); // 保存正在执行的异步任务
if (executing.length >= poolLimit) {
await Promise.race(executing); // 等待较快的任务执行完成
}
}
}
return Promise.all(ret);
}
//获取每片的blob
async function getBinaryContent(url, start, end, i) {
let result = await axios.get(url, {
headers: { Range: `bytes=${start}-${end}` },
responseType: "blob",
});
return { index: i, data: result };
}
//触发文件下载
function saveByBlob(name, blob) {
const blobUrl = URL.createObjectURL(blob);
const a = document.createElement("a");
document.body.appendChild(a);
a.style.display = "none";
a.download = name;
a.href = blobUrl;
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(blob);
}
关于并发下载:
Chrome 在 HTTP /1.1 中单个域名的请求最大 TCP 请求并发量为 6 个。
一般情况是服务器带宽大于用于带宽,且不对客户端做限制,这时候并发下载速度都会跑满客户端带宽,并不会更快。
如果服务器带宽远大于用户带宽,且限制了单个 TCP 下载速度,开启多线程下载会比单线程快,比如百度云的下载。
HTTP/2.0 多路复用代替 HTTP/1.x 的序列和阻塞机制,不受并发 6 个请求的限制,一个域名只有一个 TCP 链接。
FileSaver 下载
现成的库可以使用,适合在客户端生成文件的下载方式。
import { saveAs } from 'file-saver';
saveAs(Blob/File/URL, optional DOMString filename, optional Object { autoBom })
-
同域使用 a 标签的方式。
-
非同域, 使用 HEAD 请求判断是否支持跨域请求,支持的话则使用 blob URL 下载,否则使用 a 标签 方式。
支持条件:
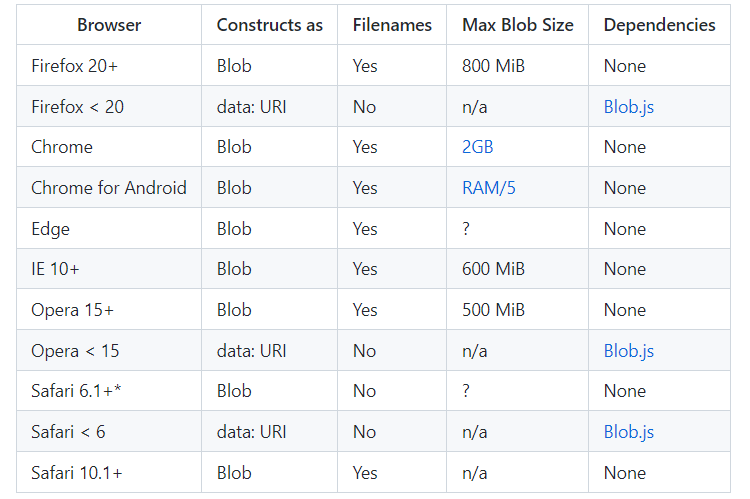
eligrey/FileSaver.js: An HTML5 saveAs() FileSaver implementation
HEAD 请求:只请求文件头,返回的响应头与 GET 方法返回的响应头一致。使用场景:判断是否支持 CORS 跨域,或在下载一个大文件前先获取其大小再决定是否要下载。
多个文件打个包下载 jszip
Stuk/jszip: Create, read and edit .zip files with JavaScript
补充知识
Blob
Blob 表示一个不可变的类似文件对象的原始数据(二进制数据)。
使用场景
- 分片上传
- 下载数据:以流的方式下载
- 用作 URL
- 转成 Base64 :fileReader.readAsDataURL
File
File 对象是特殊的 Blob,继承了 Blob 对象的属性。
FileReader 对象可以读取 File 对象的内容,异步方式,不阻碍 UI 渲染和 JS 执行。
function previewFile() {
const preview = document.querySelector('img');
const file = document.querySelector('input[type=file]').files[0];
const reader = new FileReader();
reader.addEventListener(
'load',
function () {
preview.src = reader.result;
},
false,
);
if (file) {
reader.readAsDataURL(file);
}
}
Blob URL
Blob URL/Object URL 是一种伪协议,允许 Blob 和 File 对象用作图像、下载二进制数据链接等的 URL 源。
在浏览器中使用 URL.createObjectURL 方法来创建 Blob URL,该方法接收一个 Blob 对象,并为其创建一个唯一的 URL,其形式为blob:http://localhost:3000/53acc2b6-f47b-450f-a390-bf0665e01e59 。创建的 URL 存储了一个 URL->Blob 的映射,生成的 URL 只在当前页面的打开状态有效。
Blob URL 存在副作用,Blob 本身仍然保留在内存中,浏览器无法释放,需要手动调用 URL.revokeObjectURL(url) 删除引用,允许释放内存。
ArrayBuffer
通用的、固定长度的原始二进制数据缓冲区(无法操纵其内部的原始二进制数据),不能直接读写,只能通过视图操作。
TypedArray
TypedArray 类型化数组,提供了访问原始二进制内容的能力,类型化数组是类数组对象,类似于 NodeList,arguments 等等。
是以下之一:
Int8Array();
Uint8Array();
Uint8ClampedArray();
Int16Array();
Uint16Array();
Int32Array();
Uint32Array();
Float32Array();
Float64Array();
类型化数组为了提高灵活性和扩展性,将访问二进制的实现拆分为缓冲和视图。缓冲即 ArrayBuffer,定义你想要的存储空间,而视图(即 TypedArray)提供对缓冲的访问。
理解 web 文件操作的全过程(Blob, File, ArrayBuffer) - 掘金
Blob 与 ArrayBuffer
- Blob 对象是不可变的,而 ArrayBuffer 是可以通过 TypedArrays 或 DataView 来操作。
- Blob 与 ArrayBuffer 对象之间可以相互转化:
- fileReader.readAsArrayBuffer()
- new Blob([new Uint8Array(data])
Base64 编码
一种二进制到文本(64 个可打印字符)的编码规则。
每个字符代表 6 个比特。3 个字节(3*8 个比特)的字符串/二进制文件可以转换成 4 个 Base64 字符。Base64 格式的字符串或文件的尺寸约是原始尺寸的 133%。
应用
- 存储和传输二进制数据的方式,可以用于图像、音频、视频、文本等。保证数据的完整并且不用在传输过程中修改这些数据。
解码和编码
- atob() 解码
- btoa() 编码
Data URL
data:[<mediatype>][;base64],<data>
data:text/plain;base64,SGVsbG8sIFdvcmxkIQ%3D%3D
- 浏览器中有长度限制
- 缺乏错误处理:MIME 类型错误或 base64 编码错误
Reference
<a>- HTML(超文本标记语言) | MDN- 前端常见问题和技术解决方案 - 掘金
- 文件下载,搞懂这 9 种场景就够了 - 掘金
- 【微信公众号:全栈修仙之路 2021-04-19 00:01】JavaScript 中如何实现大文件并行下载?
- Blob() - Web API 接口参考 | MDN
- 一文读懂 base64 编码 - 掘金
- js 一张图搞定 arrayBuffer/Blob/File/fileReader/canvas/base64 的各种转换操�作,以及文件上传 - 掘金
- 前端二进制 ArrayBuffer、TypedArray、DataView、Blob、File、Base64、FileReader 一次性搞清楚 - 掘金
- 你不知道的 Blob - 掘金
- ⚡️ 前端多线程大文件下载实践,提速 10 倍(拿捏百度云盘) - 掘金